Shakespeare Statistics
Die General Imposters Methode und Arden of Faversham
 in English
Alle Daten wurden mit R Stylo generiert.
Siehe:
in English
Alle Daten wurden mit R Stylo generiert.
Siehe: 
In seinem Blog "Authorship verification with the package 'stylo'" vom 30. Mai 2018 ( https://computationalstylistics.github.io/blog/imposters/)
beschrieb Maciej Eder ein neues Programmteil des Stylo-Pakets, die General Imposters Methode (GI), die von Koppel und Winter 2014
vorgestellt und von Kestemont 2016 auf die Untersuchung von Julius Caesars Schriften angewendet wurde. Eder zitiert dann die Autoren:
"Die allgemeine Intuition hinter dem GI ist nicht zu beurteilen, ob zwei Dokumente einfach im Schreibstil ähnlich sind, wenn ein
statisches Merkmalsvokabular gegeben ist, sondern es zielt darauf ab, zu beurteilen, ob zwei Dokumente signifikant ähnlicher
zueinander sind als andere Dokumente, über eine Vielzahl von stochastisch beeinträchtigten Merkmalsräumen (Eder, 2012; Stamatatos,
2006) hinweg, und im Vergleich zu einer zufälligen Auswahl von sogenannten Distraktor-Autoren (Juola, 2015), auch 'Hochstapler'
genannt."
Im Zusammenhang mit der Autorschaftszuordnung von Arden of Faversham wurden folgende Texte in Anlehnung an die Rolling Delta
Ergebnisse abgefragt:
anon_arden.txt;
chettle_hoffman.txt;
gager_ulyssesRedux.txt;
greene_friarbb.txt;
greene_orlando.txt;
kyd_soliman.txt;
kyd_spanpure.txt;
lyly_motherbombie.txt;
lyly_mydas.txt;
mar_tamburlain1.txt;
mar_tamburlain2.txt;
mars_antmellid.txt;
mars_dutchcourtesan.txt;
mun_kentcumberms.txt;
nashe_summers.txt;
peele_arraignment.txt;
peele_oldwives.txt;
row_whenysee.txt;
shak_hamlet.txt;
shak_thnight.txt;
sidney_marcantonie.txt;
wilson_3ladieslondon.txt;
Für jeden dieser Texte wurden die Häufigkeiten von Worten (mf1w), Wortbigrammen (mf2w) und Buchstabenbi- und trigrammen
(mf2c, mf3c) mit GI untersucht, wobei die Anzahl
mit 5000 bestimmt und jeweils die klassische Delta Methode (delta) eingesetzt wurde, ergänzt durch die sogenannte Würzburg Distanz (wu)
und die Ruzicka Metrik (Ru). Eder gibt folgende Einführung:
Die Hauptprozedur ist über die Funktion imposters() verfügbar. Sie setzt voraus, daß alle zu analysierenden Texte bereits
vorverarbeitet und in Form einer Matrix mit Häufigkeiten von Merkmalen (meist Wörtern) dargestellt sind. Die Funktion
vergleicht in mehreren Iterationen einen fraglichen Text mit (1) einigen Texten, die von möglichen Kandidaten für die
Autorschaft geschrieben wurden, oder den Autoren, die im Verdacht stehen, der tatsächliche Autor zu sein, und (2) einer
Auswahl von "Hochstaplern", oder den Autoren, die den zu beurteilenden Text nicht geschrieben haben können. Folglich wird
der Klasse eines Kandidaten eine Punktzahl zwischen 0 und 1 zugewiesen. Aus theoretischen Gründen würde jede Punktzahl über 0,5
darauf hindeuten, daß die Überprüfung der Autorschaft für einen bestimmten Kandidaten erfolgreich war (siehe Blog).
In dieser Untersuchung kam ein bisher unveröffentlichtes Skript von Jan Rybicki zum Einsatz, das programmtechnische Optimierungen
beinhaltet und einen grauen unsicheren Zuordnungsbereich zwischen den Werten "low" und "high" ansiedelt. Gesicherte Zuordnungen
ergeben sich hingegen oberhalb von "high".
Die Zuordnung ergab folgende tabellarische Übersicht, wobei vertikal in Spalte A die Dramentexte aufgeführt sind und
horizontal ihre jeweilige Zugehörigkeit. Die zur Anwendung gekommenen Variablen sind in Spalte Q aufgeführt.
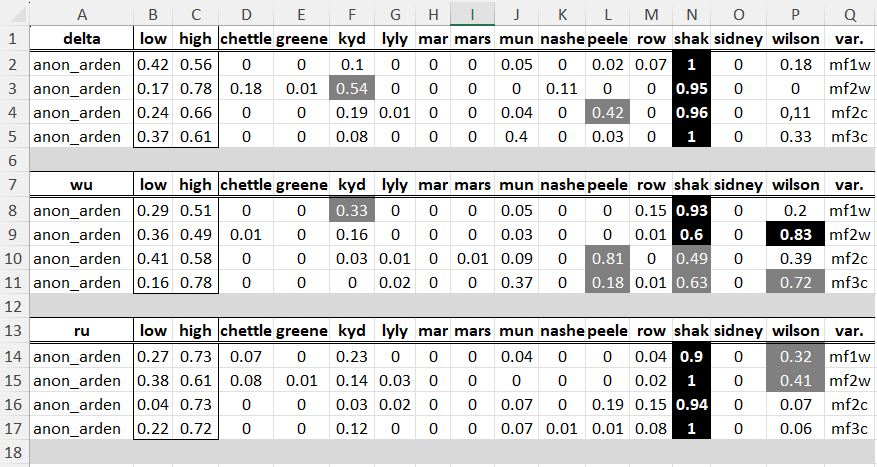
Von insgesamt 13 Werten oberhalb von "high" benennen 10 Shakespeare als Autor. Die größte Streuung zeigt sich wie so
häufig bei der Cosine Delta Distanz. Laut Kestemont at al. besitzt die Ruzicka Metrik die größte Genauigkeit.
br>
Vergleiche die General Imposters Ergebnisse mit jenen von Rolling Delta und Rolling Classify