Shakespeare Statistics
The General Imposters Method and Arden of Faversham
 in German
All data were generated with R Stylo.
See:
in German
All data were generated with R Stylo.
See: 
In his blog "Authorship verification with the package 'stylo'" of May 30, 2018 Maciej Eder (https://computationalstylistics.github.io/blog/imposters/) described a new feature of the stylo package 'namely the General Imposters (GI) method, also referred to as the second verification system, introduced by Koppel and Winter (2014) and applied to the study of Julius Caesar's disputed writings (Kestemont et al., 2016a).' Eder then quotes the authors: "[t]he general intuition behind the GI, is not to assess whether two documents are simply similar in writing style, given a static feature vocabulary, but rather, it aims to assess whether two documents are significantly more similar to one another than other documents, across a variety of stochastically impaired feature spaces (Eder, 2012; Stamatatos, 2006), and compared to random selections of so-called distractor authors (Juola, 2015), also called 'imposters'." (Kestemont et al., 2016a: 88). In the context of the authorship attribution of Arden of Faversham the following play texts were in the corresponding folder:
anon_arden.txt; chettle_hoffman.txt; gager_ulyssesRedux.txt; greene_friarbb.txt; greene_orlando.txt; kyd_soliman.txt; kyd_spanpure.txt; lyly_motherbombie.txt; lyly_mydas.txt; mar_tamburlain1.txt; mar_tamburlain2.txt; mars_antmellid.txt; mars_dutchcourtesan.txt; mun_kentcumberms.txt; nashe_summers.txt; peele_arraignment.txt; peele_oldwives.txt; row_whenysee.txt; shak_hamlet.txt; shak_thnight.txt; sidney_marcantonie.txt; wilson_3ladieslondon.txt;
For each of these texts, word and word bigram frequencies and the frequencies of character bi- and trigrams were examined with GI, and their number was determined with 5000. The classical delta method was used in each case, supplemented by the so-called Würzburg distance and Ruzicka metrics. The main procedure is available via the function imposters(). It assumes that all the texts to be analyzed are already pre-processed and represented in a form of a matrix with frequencies of features (usually words). The function contrasts, in several iterations, a text in question against (1) some texts written by possible candidates to authorship, or the authors that are suspected of being the actual author, and (2) a selection of "imposters", or the authors that could not have written the text to be assessed. Consequently, a given candidate's class is assigned a score between 0 and 1. On theoretical grounds, any score above 0.5 would suggest that the authorship verification for a given candidate was successful (quote from Eder's blog). In this investigation a so far unpublished script by Jan Rybicki was used which contains an optimised program version that returns the grey area of insecure attributions between the values "low" and "high". Only values above "high" point to authorship. The allocation resulted in the following tabular overview:
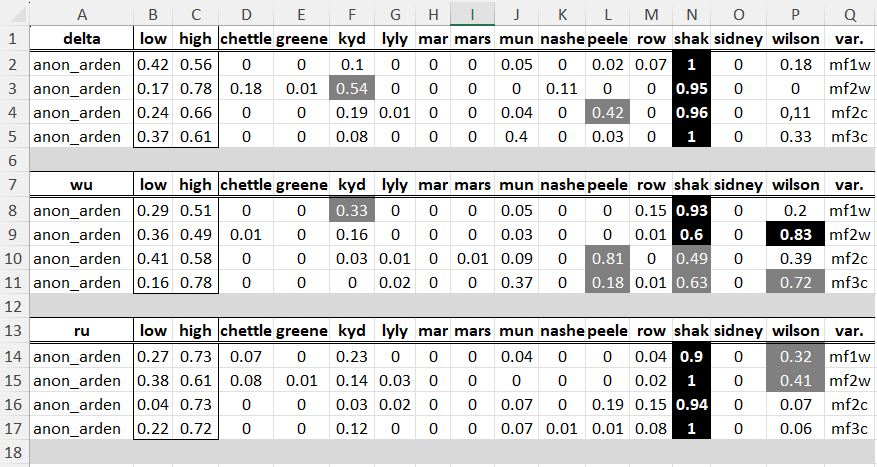
All in all there are 13 values above "high" of which 10 are taken by Shakespeare. The somewhat brittle cosine delta shows some dispersion whereas the Ruzicka metrics are most reliable.