Inhalt
Geschichtliches, Textvoraussetzungen Beispiele,
Die ersten Anfänge des Dramenanalyseprogramms
gehen in das Jahr 1984 zurück. Einzelne Analyseschritte wurden von Thilo
Schrumpf thilo.schrumpf@freenet.de in
Microsoft-Basic auf einem alphatronic PC 8 mit CP/M Betriebssystem programmiert.
1987 erfolgte seine Zusammenfassung des gesamten Programms in Turbo-Basic
für MS-DOS Computer. Die graphische Auswertung der Basisdaten durch ein eigenes
Graphikprogramm begann 1993. Die Software-Programmierung in Turbo-Pascal
wurde von Carsten Kirck durchgeführt. Auf der Basis des MS-DOS Programms
wurden die Daten für die quantitativ-statistische Analyse der Shakespeare-Dramen
ermittelt, die 1998 beim Peter Lang Verlag erschienen ist. Im gleichen Jahr
wurde die erste Umschreibung in Visual Basic für Windows realisiert. Während
Frank Roggatz roggi@gmx.de den Programmcode erstellte, sorgte Fred Nordmann nordmann@frog-edv.de für die Sicherung und Auswertung der Daten im Datenbank-Programm
Access.
Die Weiterentwicklung des Dramenanalyseprogramms zur Nutzung über das
Internet wurde von Bogdan Vlasenko in Java 2.0 programmiert.
(I)nternet (D)rama (A)analysis (P)rogramme (IDAP) hat die Adresse
http://idap.engsem.uni-hannover.de
Vorbereitung der Dramentexte
Dramentexte eignen sich von ihren formalen Voraussetzungen her besser für quantitative Textanalysen als andere Textsorten. Auf Grund des äußeren Erscheinungsbildes lassen sich Sprecher und Replik leicht unterscheiden, vor allem deshalb, weil in den meisten Editionen der Sprechername groß geschrieben ist. Für die Replik läßt sich die Unterscheidung in Haupt- und Nebentext treffen, und insofern als auch ungebundene Nebentextinformationen in die Klammern "<" und ">" gefaßt und der nächsten Replik zugeordnet werden, besteht der gesamt Text nur noch aus einer Abfolge von Repliken. Jede Replik beginnt mit einem Sprechernamen, der dem Programm aus der Figurenliste bekannt ist, und endet mit der Absatzendemarke. In der Auswertung werden Nebentext und Haupttext wieder voneinander getrennt.
Die Programmanweisungen, die Auftritte und Abgänge sowie Beiseitesprechen anzeigen, sind keine Bestandteile des Textes und werden daher nicht quantitativ ausgewertet. Programmanweisungen sind die die eckigen Klammern "[ und "]" eingebettet. Da Texteditionen und Internettexte unterschiedliche Notationen verwenden, ist in einem ersten Schritt der Textaufbereitung darauf zu achten, daß alle Nebentextinformationen ausschließlich in spitzen Klammern erscheinen, alle programmrelevanten Anweisungen in eckigen Klammern. Nachfolgend eine Liste wichtiger Punkte, die unbedingt beachtet werden sollten:
1. Großschreibung des Sprechernamens vor der Replik.
2. Nebentext erscheint in spitzen Klammern <Nebentext> in der laufenden Replik.
3. Der in die Replik eingefügte Nebentext enthält auch Nebentextinformationen wie Akt- und Szenenbeginn oder Ortsangaben, die sonst vor der Replik stehen
4. Der Auftritt einer Figur wird als[Enter·FIGUR]notiert.
a. Analog dazu der Auftritt mehrerer Figuren in Form einer Figurenliste
[Enter·FIGUR1·FIGUR2·FIGUR3·FIGUR4·FIGURn+1]
5. Abgänge von Figuren erscheinen in der Replik als [Exit·FIGUR]
a. Abgänge mehrerer Figuren entsprechend 4 a.
b. Verläßt die Figur die Bühne unmittelbar nach der Replik, genügt an
deren Ende die Notation [exit]
6. Treten alle Figuren ab (Konfigurationswechsel), erscheint in selbständiger Zeile [Exeunt]
7. Beiseitesprechen kann dem Programm durch [aside] angezeigt werden.
8. Der Tod einer Figur wird mit [FIGUR·dead] notiert.
9. Beliebige Kombination der Indikatoren Enter, Exit, Aside, Dead sind im Nebentext möglich, wenn die Anweisungen durch einen Punkt getrennt sind, also z.B.die Notation [exit·FIGUR2. ·enter·FIGURn+1]
10. Die Leerstelle nach dem Punkt im vorstehenden Beispiel ist unverzichtbar und wurde mit dem Zeichen "·" dokumentiert.
11. Gelegentlich werden Repliken in Texten mit ALL angekündigt. Das Programm reagiert darauf, wenn in der vorhergehenden Replik im Nebentext erklärt ist, wer oder was unter ALL zu verstehen ist. [ALL·=·FIGUR1·FIGUR2·FIGURn+1.]
13. Die Gültigkeit der Definition erlischt mit dem Abgang von Figuren und muß in neuen Konfigurationen erneuert werden.
14. Während die beiden Programmanweisungen [ACT·3·SCENE·2] und [Exeunt] in einer selbständigen Zeile stehen, und zwar vor bzw. nach der Replik, werden alle anderen Notation Auftritte oder Abgänge betreffend [enter ...], [exit ...] in die Replik hineingeschrieben. Ebenso Beiseitesprechen [aside] und die All-Definition.
15. Wird die ALL-Liste zu umfangreich, ist auch die "negative" Definition möglich,z.B. in der Notation [ALL·EXCEPT(BUT) ·FIGUR1]. Jetzt wird wirklich das gesamte dramatische Personal auf sprechend gesetzt mit Ausnahme von Figur1.
16. Laufzeitfehler und andere Fehlermeldungen des Programms lassen sich regelmäßig auf fehlerhafte Notationen zurückführen. Ein typischer Ausstiegspunkt des Programms ist zum Beispiel, wenn es auf einen Sprechernamen stößt, der nicht in der Figurenliste enthalten ist. Dies ist auch im folgenden der Fall:
··RICHARD
RICHARD steht zwar in der Figurenliste, aber eben ohne die beiden Leerzeichen
17. Der nachfolgende unformatierte Text ist jetzt programmgemäß. Lediglich zur Unterscheidung sind Programmanweisungen hier in rot, Sprecher in blau und Nebentext in grün gefaßt, während der Sprechtext schwarz blieb.
[ACT·1·SCENE·2]¶
RICHARD <The king's Palace. Enter RICHARD, QUEEN ANNE, GUARD, BUCKINGHAM, all heavily armed.>bla bla bla bla bla!<Exeunt> [Enter·QUEEN·ANNE·GUARD·BUCKINGHAM]¶
[Exeunt]¶
18. Das Programm erkennt als erstes die Aktangabe und die Szenennummer,
sodann identifiziert es RICHARD als Sprecher der Replik. Queen Anne, die
Wache und Buckingham werden auf anwesend gesetzt. Wichtig ist, daß RICHARD
in der Enter-Programmanweisung nicht enthalten ist, denn er spricht ja schon.
Der Eintrag würde Richard auf anwesend zurücksetzen, sollte er hier hinzugefügt
worden sein. Das selbständige Exeunt setzt für die nächste Replik alle Anwesenden
auf abwesend zurück. Akt- und Szenenangabe, aber auch der totale Konfigurationswechsel
stehen in selbständiger Zeile. Vor oder hinter den Klammern dürfen keine
weiteren Zeichen stehen.
Während die o.a. Textkonditionierungen auch für IDAP gelten, sind
alle nachfolgenden Information auf die nicht mehr verfügbare Windrama
Version bezogen und haben nur noch dokumentarischen Charakter. (Anweisungen zu IDAP-Analysen siehe p.pdf)
Im Regelfall befinden sich die Programmdateien nach der Installation im Verzeichnis C:\Programme\Dramenanalyse auf dem PC
Es handelt sich um die Dateien dramax2.exe, dramax2.dep, dramenanalyse.ttf, windrama.mdb und windrama.hlp. Es wird empfohlen, die zu analysierenden Dateien in das Unterverzeichnis Daten zu kopieren, um keine unübersichtlichen Situationen zu produzieren. Wichtig ist, daß windrama.mdb im gleichen Verzeichnis ist wie die beiden ASCII-Textdateien name.txt und name.chr, wobei name zu ersetzen ist durch den Namen des ausgewählten Dramentextes.
Einige Konvention in der Namensgebung erleichtern die Identifikation.
|
Name |
Endung |
Beschreibung |
|
6HENRY21 |
TXT |
ASCII-Text Henry VI, zweiter Teil, erster Akt |
|
5HENRY0 |
TXT |
ASCII-Text Henry V, Gesamttext, alle Akte |
|
6HENRY35 |
TXT |
ASCII-Text Henry VI, dritter Teil, fünfter Akt |
|
RICH30 |
CHR |
ASCII-Text Richard III, Personenliste |
|
RICH30 |
TXT |
ASCII-Text Richard III, Gesamttext, alle Akte |
|
RICH30 |
KNF |
Auswertung Richard III, Konfigurationsstruktur |
|
RICH30 |
STA |
summarische Auswertung von Richard III |
|
RICH30 |
RPL |
ASCII-Text Replikennummer, Sprecher, Text von R.III |
Das Programm startet durch Aufruf von dramax2.exe.
Unter Datei wird Dramentext auswerten angeklickt.
und anschließend der Text ausgewählt.
mit dem Öffnen der Textdramendatei öffnet sich ein Fenster und die quantitative Analyse beginnt.
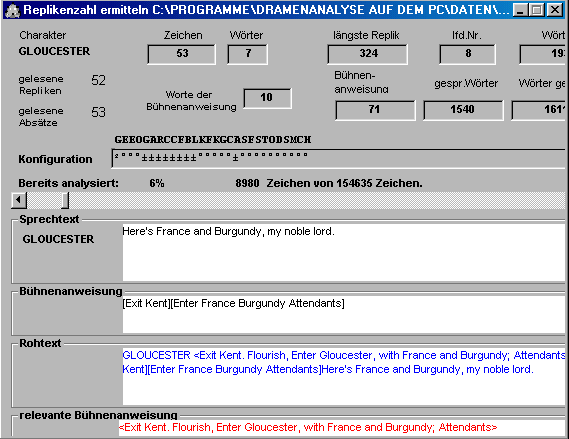
Evtl. Programmabbrüche liegen mit Sicherheit an der unvollständigen Aufbereitung des Textes. (siehe Fehlerbehandlung). Läuft das Programm ohne Beanstandungen durch, so erscheint:
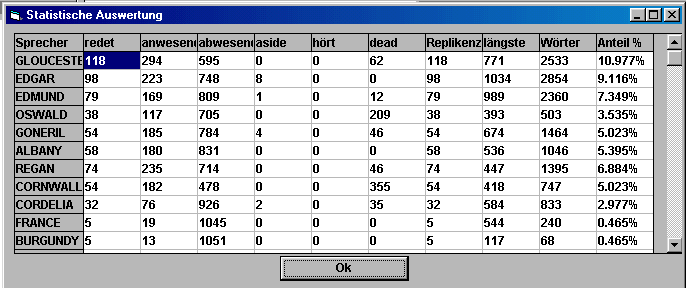
und mit der Bestätigung OK wird die Summenauswertung am Bildschirm angezeigt, die quantitative Dominanzrelationen des Personals verdeutlicht und im Verzeichnis an der Dateiendung ".sta" erkannt wird.
Es ist an dieser Stelle bereits möglich, nach dem Schließen der Übersichtsstatistik im Pulldownmenu des Programms den Auftrittsdichtewert angezeigt zu bekommen. Dazu wählen wir im Menu aus:
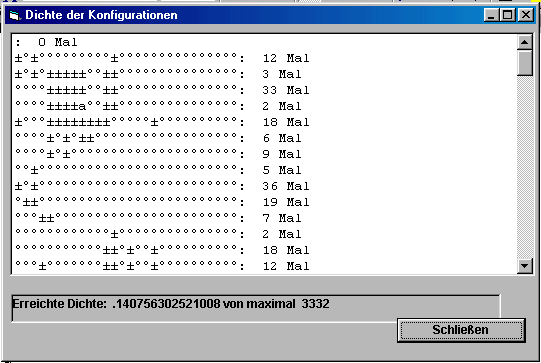
Es erscheint der nachfolgende Ausschnitt. Aus der Matrix, die horizontal das Personal abbildet und vertikal die Replikenabfolge, ist aus dem Verhältnis der besetzten Stellen (anwesenden Figuren) zur Gesamtzahl aller Matrixzellen der Quotient gebildet worden. Durch die Verlagerung des Kommas um zwei Stellen nach rechts ergibt sich die prozentuale Formulierung: x Prozent des Personals sind durchschnittlich anwesend. Außerdem gibt die Übersicht an, wie häufig bestimmte Konfigurationen vorkommen. Gemessen wird die Replikenzahl.
Mit der Auswahl "Ende der Dramenanalyse" ist die unmittelbare Auswertung abgeschlossen.
Im Verzeichnis befindet sich jetzt eine Datenbankdatei mit dem Namen des bearbeiteten Dramentextes und der Endung ".mdb". Diese Datei wird durch Doppelklick aufgerufen.
Es öffnet sich ein Fenster, das eine Initialisierung der Daten anbietet und mit OK bestätigt werden muß.
Nach kurzer Zeit erfolgt die Bestätigung.
Durch Anklicken von OK rufen wir ein neues Fenster auf, das als Hauptübersicht fungiert und später alle dramenanalytischen Funktionen verfügbar machen soll.
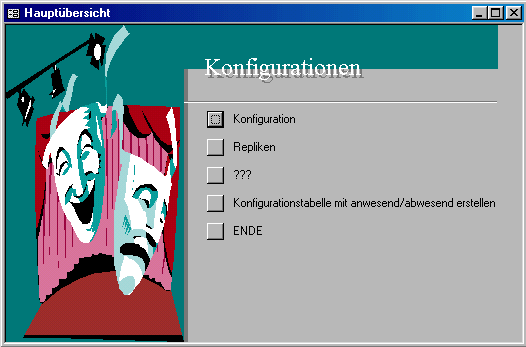
Hier klicken wir: Konfigurationstabelle mit anwesend/abwesend erstellen.
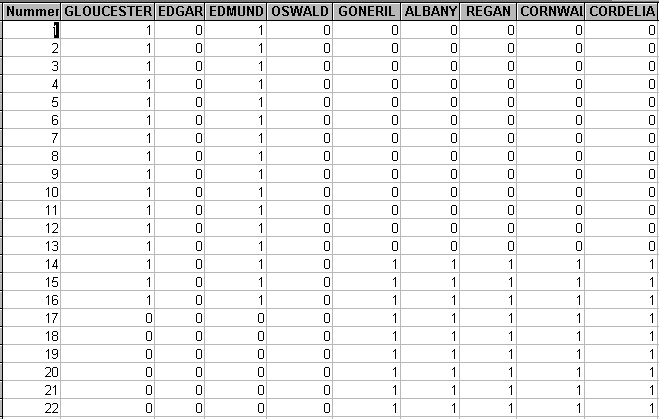
Die daraus resultierende Tabelle enthält horizontal das Personal und vertikal die Replikenabfolge. Für jede Replik und Figur wird mit den Werten 1 und 0 An- oder Abwesenheit notiert. Die Summe der Figurenspalten ergibt den Konfigurationsumfang pro Replik. Die Summe der Zeilen ergibt pro Figur die Anwesenheit (einschl. eigener Repliken). Die Tabelle enthält die Informationen, um in weiteren Schritten für jedes Figurenpaar die szenische Nähe, bzw. Distanz zu berechnen oder die Replikenzahl gemeinsamer Anwesenheit zu ermitteln.
Mit Ende wird die Access-Datei geschlossen. Bis die Übersicht alle Analyseverfahren bereitstellt, klicken wir auf das Kreuz in der rechten oberen Ecke. Jetzt schließt sich nur die Hauptübersicht, aber wir bleiben im Access-Programm und haben nun Zugang zu Tabellen, Abfragen, Formularen, etc.

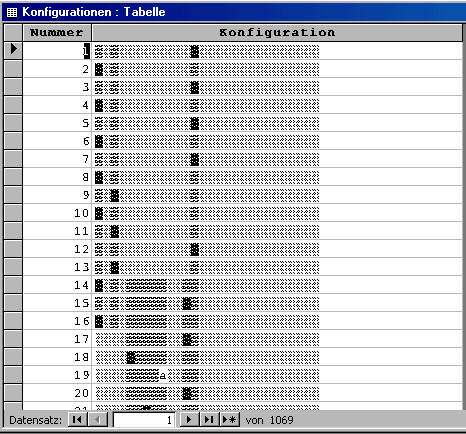
Öffnen wir Konfigurationen, so erhalten wir die nachstehende Konfigurationsstruktur. Die graphischen Symbole bezeichnen für jede Replik und Figur die Zustände sprechend, anwesend und abwesend. Darüber hinaus gibt es Sonderzeichen für das Beiseitesprechen und für den Tod einer Figur. In der Abfolge der Repliken lassen sich totale und partielle Konfigurationswechsel optisch übersichtlich erfassen, und in ihrer umgewandelten Form als Textdatei lassen sich eigene Ergänzungen einfügen, z.B. hinsichtlich der Spannungsbögen, der Gruppierungen des Personals, des Wechsels von Ort und Zeit, etc.
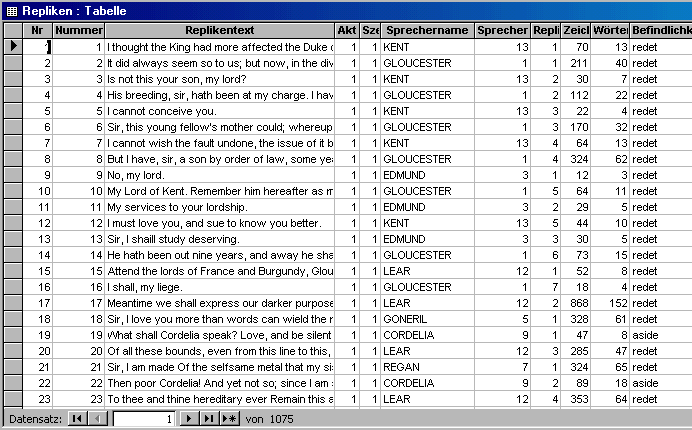
Mit dem Aufruf der Tabelle Repliken gelangen wir zur zentralen Datenbank, in der eine ganze Reihe von Angaben gespeichert sind. Viele dieser Daten werden für weitere Abfrageprozeduren benötigt. Die Tabelle hat folgendes Aussehen:
Schließen wir die Tabelle, bietet es sich als nächstes an, einen Blick auf die Tabelle Sprecher zu werfen. Auch diese Tabelle wird für weitere Abfragen benötigt.

Unter den Abfragen sind zur Zeit nachfolgende Auswertungen zu sehen.
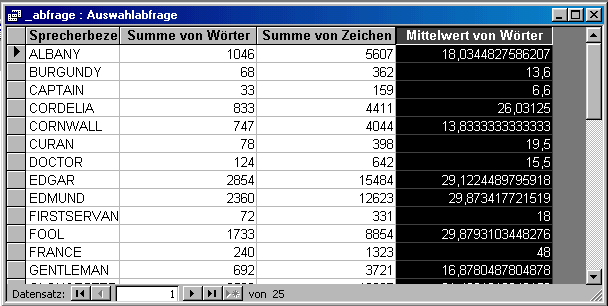
Hinter "_abfrage" verbirgt sich eine Tabelle, die die Wort- und Zeichenanzahl für jede Figur angibt, und außerdem die durchschnittliche Replikenlänge in der Anzahl der Worte.
Die Abfrage Akt-Szenenbeginn hält vertikal die Anzahl der Akte und horizontal die Anzahl der Szenen pro Akt fest und gibt die Replikennummer an, mit der der Akt oder die Szene beginnt.

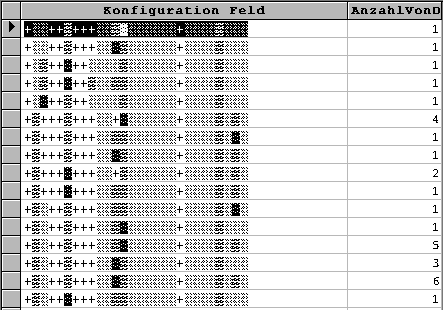
Die Abfrage "Duplikate suchen zu Konfigurationen" enthält die gleichen Informationen wie die Grafik aus dem Programmteil Konfigurationsdichte. Der einzige Unterschied ist der, daß die Konfigurationsdichte nicht noch einmal benannt wird. Für jede Konfiguration wird aber jetzt in graphisch unterschiedenen Symbolen An- oder Abwesenheit sowie der Tod ausgedrückt sowie die Anzahl des Vorkommens.
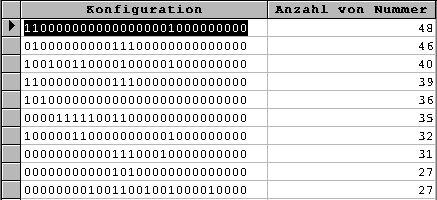
Die Abfrage "Duplikate suchen zu Konfigurationen nur als anwesend/abwesend" enthält die bereits nach Häufigkeit sortierte Liste von Konfigurationen. An- und Abwesenheit sind binär mit 0 und 1 notiert.
Die Abfrage "Duplikate suchen zu Repliken" spiegelt in der Formulierung den programmtechnischen Vorgang wieder. Gemeint ist, daß für jede Figur Repliken in Wort- und Zeichenanzahl aufgeführt werden werden. Man kann die Auflistung auch als Sortierung aller Repliken des Dramentextes nach den Sprechern verstehen. Ihre Bedeutung hat die Liste in der Möglichkeit, Häufigkeitsverteilungen der Replikenlängen für das relevante Personal sowie für den Gesamttext zu erstellen.
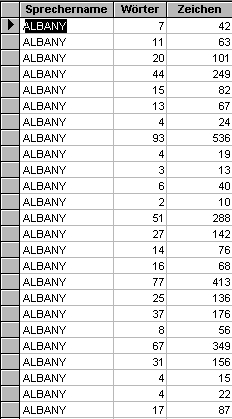
Die Abfrage "Gesamtsumme" enthält die Gesamtsumme an Repliken, Wörtern und Zeichen. Die erste Spalte jedoch zeigt bei Differenzen zur zweiten Spalte an, wie oft mehrere Sprecher zugleich antworten (Notation = ALL). Die Differenz 6 besagt, daß entweder einmal 6 Personen zugleich identisch antworten, oder zweimal 3 Personen, oder dreimal zwei Personen.

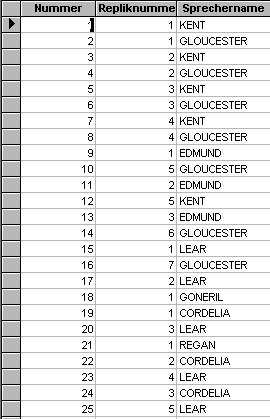
Die "Replikenabfrage" enthält die fortlaufend numerierten Repliken des Textes und zu jeder Replik die Angabe, um die wievielte Replik der Figur es sich handelt.
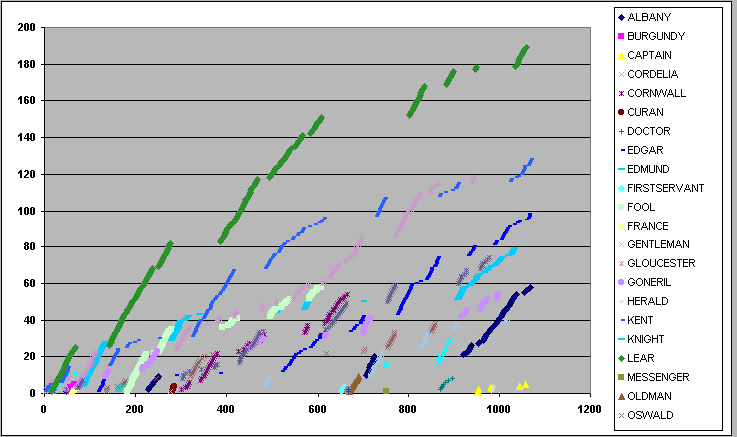
Aus der Replikenabfrage wird in der Rubrik Formulare unter der Bezeichnung "Tabelle_fig_rep" eine Grafik generiert, die die Textrepliken auf der x-Achse und die Figurenrepliken auf der y-Achse abbildet, und das funktionale Zusammenspiel von Figuren veranschaulicht.
In der Rubrik Formulare befinden sich keine neuen Informationen, lediglich Oberflächenwindows für die bisher benannten Inhalte.
... (wird fortgesetzt) 04.07.01