|
Die Rolling Classify Untersuchung verwendet die Klassifikatoren nsc (nearest shrunken centroid),
svm (support vector machine) und delta, die jeweils auf die häufigsten Funktionswörter und auf die häufigsten Buchstabenbi-
und trigramme angewendet wurden. Eine Präzisierung der Ergebnisse ergab sich wiederum durch die methodische Verbesserung der
Verwendung einer Gesamtheit von Referenztexten, die nur einen Autor haben und die eindeutig zugeordnet sind. Der Rückgriff
auf wenige Kerntexte größerer Korpora verhindert mögliche Beeinträchtigungen durch die Textmenge.
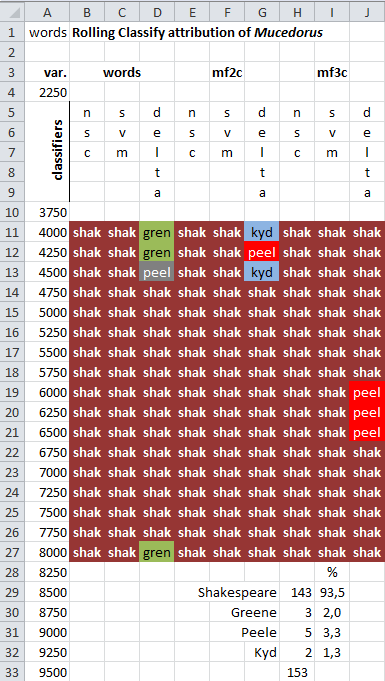
Als Fenstergröße wurden 8000 Worte bei einer Überlappung von 7750 Worten gewählt, so dass sich eine Vergleichbarkeit
mit Rolling Delta Dateien einstellte. Entsprechend ihres mathematischen Kerns gewichten die Klassifikatoren unterschiedlich. Nsc hat einen
niedrigen Entscheidunglevel, svm einen sehr hohen und ist daher zu bevorzugen. Buchstabentrigramme scheinen auch hier genauer zu sein
als Wort- und Bigrammklassifikationen.
Die Auszählung der Matrixzellen und der prozentualen Autorenzuschreibung befindet sich am Ende der Tabelle. |
 in English
Alle Daten wurden mit R Stylo generiert (.
Siehe:
in English
Alle Daten wurden mit R Stylo generiert (.
Siehe:  ).
).